Bayer pattern is a common term you will come across while working with a digital camera. Wikipedia does a great job at explaining the Bayer pattern: wiki
Bayer Pattern:
The most straightforward explanation is you have a CCD with three types of photo sensors(red, green and blue). Green are sensitive to luminance and red and blue are sensitive to chrominance(color). Apparently, human eyes are more sensitive to luminance so in a typical CCD you will have twice as many green sensors as the red and blue ones. These photo sensors are arranged in a specific pattern(RGBG, GRBG, RGGB). The raw output(also referred to bayer pattern image) will record only one of the three colors at each photo sensor. Each photo sensor has a corresponding pixel in the image. From the bayer pattern we only have the raw value at each pixel but we want to know the true color(r,g,b). This process of computing the color at each pixel is called demosaicing(or debayering?). A typical arrangement of photo sensors is shown in the image below ( linked from Wikipedia ).
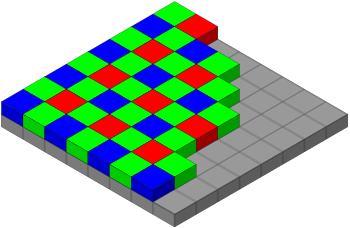
Demoasicing:
There are number of methods out there that do demosaicing and a survey of all the techniques is out of scope of this post. I myself implemented three techniques which are intuitive, computationally less expensive and work reasonably well.
This is the first thought that will come to anybody's mind:
For each pixel do bilinear interpolation. So depending on where you are in the pattern the bilinear interpolation will vary. For example in the above image if you are on the green with two reds on top and bottom, you will just take the average of the red value. But, if you are on the blue you will take average of all four neighboring reds etc. This approach works reasonably well but artifacts (aliasing, zippering, purple fringing etc.) show up on the edges. These are quite noticable.
Since most of the artifacts are on/near the edges, instead of blindly doing bilinear interpolation you do edge aware interpolation. For example below if you are trying to find the green value at position B, you will only take the average of the green values with smaller gradient. i.e. first you compute the difference of horizontal green values and vertical green values and pick the option with lower difference and take the average of those two green values. This change makes the demosaicing much better.
grgrg
bgBgb
grgrg
Edge Aware Weighted:
Taking it a step further instead of blindly discarding the two green values with higher gradient we take a weigh the horizontal and vertical ones according to the gradient values. Lets define the following:
HDiff = LeftGreen - RightGreen
HSum = LeftGreen + RightGreen
VDiff = TopGreen - BottomGreen
VSum = TopGreen + BottomGreen
Final = 0.5 * (VSum * HDiff + HSum*VDiff ) / (HDiff + VDiff)
I will leave it to your intuition why 0.5 is needed :-) This small extension is less prone to noise and also keeps strong edges intact.
This drastically improves results. There might be even more fancier ways but for now I fixed my issue so I will research further in future! For comparison purposes I am including the sample images after using the normal(left) and edge aware weighted(right) . Observe across the edges on the chair, board and any other place. You can judge the difference yourself..


1 comment:
For a long time now, robotics folks have harped on the idea of
"grounded representations". As in, the idea that your models are
only meaningful when you can follow them down to observable
properties and predictions in the real world. This generally
applies to representations about objects and stuff: a robot
understands a cup better than an image retrieval algorithm,
because it understands the affordances or dynamics of the cup.
So here's my thought: perhaps many concepts are only really
learned/usable only when they're grounded out in (perhaps many of)
the abstractions they're built on. This as opposed to being an
abstract computational object that's usable right away, as soon as
its referents become available. For example, maybe I could pick
up an algebraic topology book and read all about manifolds, and
then hit the ground running in a computer graphics course. More
likely though, it'd be easier to go the other way around: knowing
that a manifold might be used to describe the surface of a lake
somehow HELPS understand that in a manifold "every point has a
neighborhood homeomorphic to an open Euclidean n-ball".
The thing that made me think of this was the POMDP stuff I was
reading today. When I first took Mike's class in 2008, POMDP math
was a mystery to me - I had no hope of understanding how it
worked. Interestingly, I had read explanations of bayes rule many
times, but didn't really *get it*.
However, sometime between 2008 and now I learned a bit about MDPs.
In particular, from the humanoids paper, quals, the PGSS project,
the NAMO project, and that ISYE stats class, I got a solid
understanding for what it meant to take an expectation over
rewards or transitions in an MDP. I knew the words before, but
now i've done it on paper and in code. And it turns out that
having done those things made it easy to understand the belief
updates for the POMDP, despite the fact that i'd read all about
expectations and bayes rule before 2008. Somehow, without
knowingly drawing an analogy to expected rewards, the belief state
updates made perfect sense.
So what gives? If the theory that learning of abstract concepts
is modular to those abstract structures, then they should be
happily in place for me to apply to POMDPs. The only catch should
be that I can't get any further than I did with MDPs.
There's all sorts of problems with these explanations and
examples, but what I'm trying to say is that I'm suspicious of the
idea of strong modularity of mind. As I think any expert in
anything would attest, abstract knowledge is won through years of
experience, in which presumably you're fleshing out the semantics
of the abstract concepts from bottom to top.
Or as frank puts it, "math isn't something you learn, it's
something you get used to".
Post a Comment